COMPASS: Generalizable AI for Predicting Cancer Immunotherapy Response
We are excited to share our recent paper, Generalizable AI predicts immunotherapy outcomes across cancers and treatments, published in Nature Medicine. In this work, we introduce COMPASS, a pan-cancer foundation model that predicts response to immune checkpoint inhibitors from pretreatment bulk tumor transcriptomes.
The study was led by collaborators across Harvard Medical School, Roche Pharma Research and Early Development, and Zhejiang University. COMPASS reflects a central goal of our research program: to build AI systems that are not only accurate, but also generalizable, biologically interpretable, and useful for translational oncology.
Why Immunotherapy Response Prediction Remains Hard
Immune checkpoint inhibitors have changed cancer treatment, but durable benefit is still limited to a subset of patients. In clinical practice, biomarkers such as PD-L1 expression, tumor mutational burden, microsatellite instability, CD8+ T cell infiltration, and immune gene signatures can be informative, but they often fail to generalize across tumor types, therapies, platforms, and patient populations.
This is exactly the setting where clinical AI faces its hardest test. Patient cohorts are small, treatment labels are expensive to collect, cancers are biologically heterogeneous, and the input space contains tens of thousands of genes. A model trained narrowly on one cohort can easily overfit and fail when moved to a new cancer type, hospital, sequencing platform, or treatment setting.
The Core Idea: A Concept Bottleneck Foundation Model
COMPASS was designed around a simple but powerful principle: rather than forcing a model to jump directly from thousands of gene-expression values to a response label, we guide it through biologically meaningful intermediate concepts.
Starting from expression profiles of 15,672 protein-coding genes, COMPASS uses a transformer-based gene encoder and a hierarchical concept projector to organize tumor transcriptomes into a compact concept-level representation of the tumor immune microenvironment. These concepts capture immune cell states, tumor–microenvironment interactions, stromal and endothelial programs, and signaling pathways that are relevant to immunotherapy response.
The model maps gene-expression information through immune gene signatures into 44 patient-level concepts: 43 biological concepts plus one cancer token. These concepts cover T cells, B cells, NK cells, macrophages, IFNγ signaling, TGFβ signaling, endothelial exclusion, genome integrity, proliferation, and other processes central to tumor immunity.
This architecture makes COMPASS different from many black-box predictors. The model is not just asked to output “responder” or “non-responder.” It first builds a patient-specific immune map, then uses that map to support prediction and interpretation.
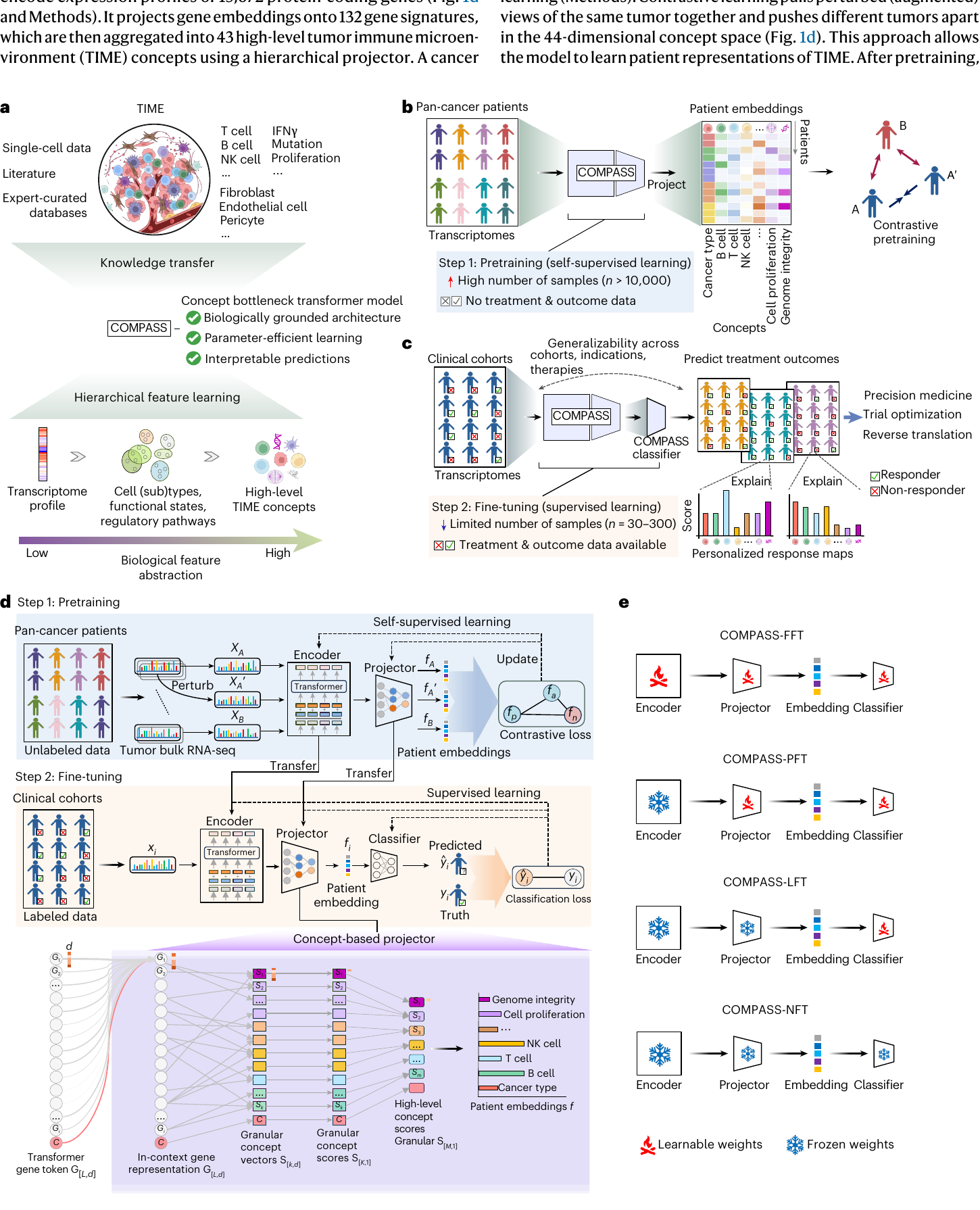
Learning from Large Pan-Cancer Data, Adapting to Small Clinical Cohorts
A major challenge in precision oncology is that clinical immunotherapy cohorts are often small. COMPASS addresses this through a transfer-learning strategy. The model is first pretrained on 10,184 tumor transcriptomes from The Cancer Genome Atlas across 33 cancer types using self-supervised contrastive learning. It then adapts to clinical immunotherapy cohorts through flexible fine-tuning strategies.
This design gives COMPASS an important advantage: it can transfer broad tumor-immune knowledge learned from large unlabeled pan-cancer data into much smaller labeled clinical datasets. In other words, COMPASS is built for the reality of translational medicine, where the most valuable cohorts are often the smallest.
Beyond Fixed Gene-Set Scoring
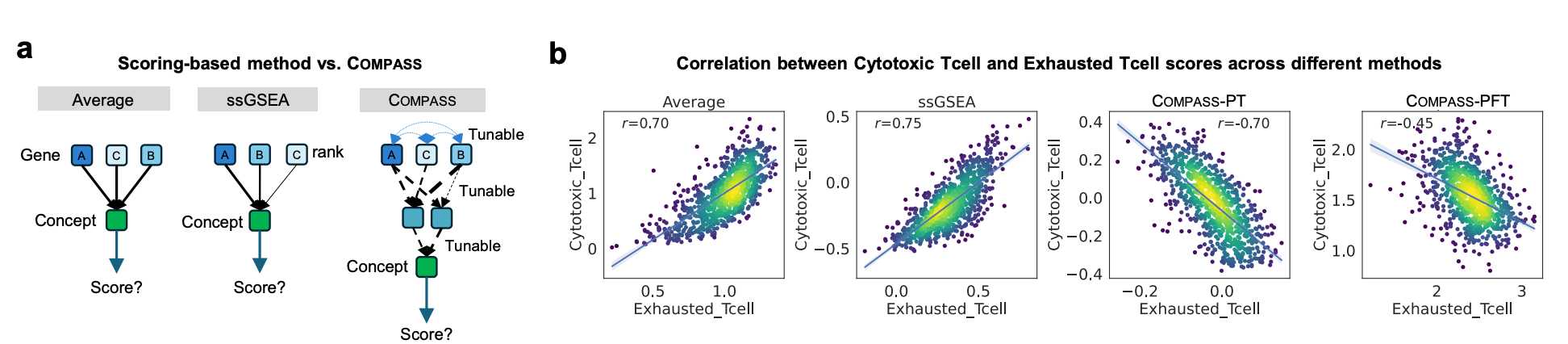
Traditional gene-set scoring methods, including non-parametric approaches such as ssGSEA, are useful because they summarize biological programs in an interpretable way. However, they usually score each signature independently and do not learn how genes, signatures, concepts, cancer context, and treatment response interact across cohorts.
COMPASS keeps the interpretability of gene programs while adding representation learning. It learns context-aware gene embeddings, maps them into structured immune concepts, and adapts those concepts for response prediction. This makes the model more flexible than fixed scoring while still preserving a biologically readable bottleneck.
A concrete example is the relationship between cytotoxic T cell and exhausted T cell concepts. Fixed scoring methods can show a strong positive correlation because the two gene sets overlap substantially. After fine-tuning, COMPASS learns a negative relationship that better reflects the biological tension between cytotoxic function and T cell exhaustion.
Performance Across Cancers and Treatments
We evaluated COMPASS on 1,133 patients from 16 clinical immunotherapy cohorts spanning seven cancer types and six immune checkpoint inhibitor regimens. All samples were pretreatment bulk RNA-seq profiles, making the task clinically relevant: predict response before therapy begins.
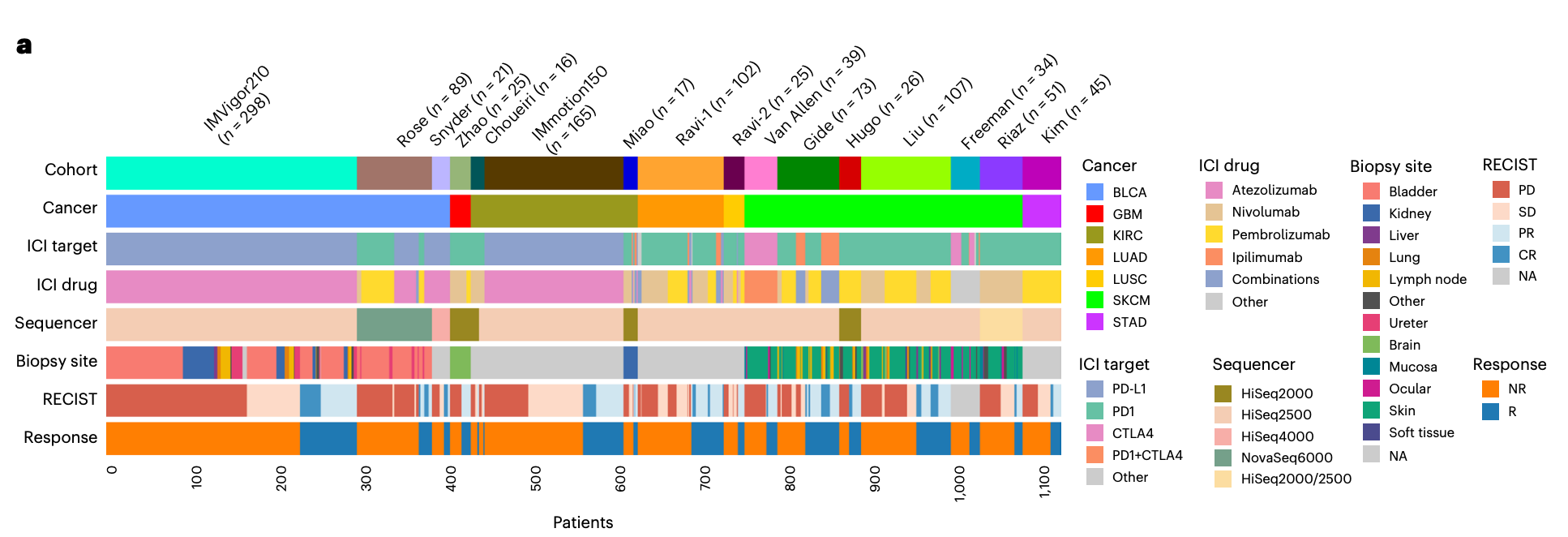
Across leave-one-cohort-out evaluations, COMPASS achieved stronger average performance than 22 published or widely used response-prediction methods. Compared with the best competing methods, COMPASS improved accuracy by 8.5%, AUPRC by 15.7%, and MCC by 12.3% on average. Importantly, the model generalized not only across cohorts, but also to cancer types and treatments not represented during fine-tuning.
For example, a model trained only on PD-1/PD-L1 cohorts could predict CTLA-4 treatment response, and a model trained on monotherapy cohorts could predict response to combination therapy. These results suggest that different immunotherapy strategies share transferable tumor-immune response patterns.
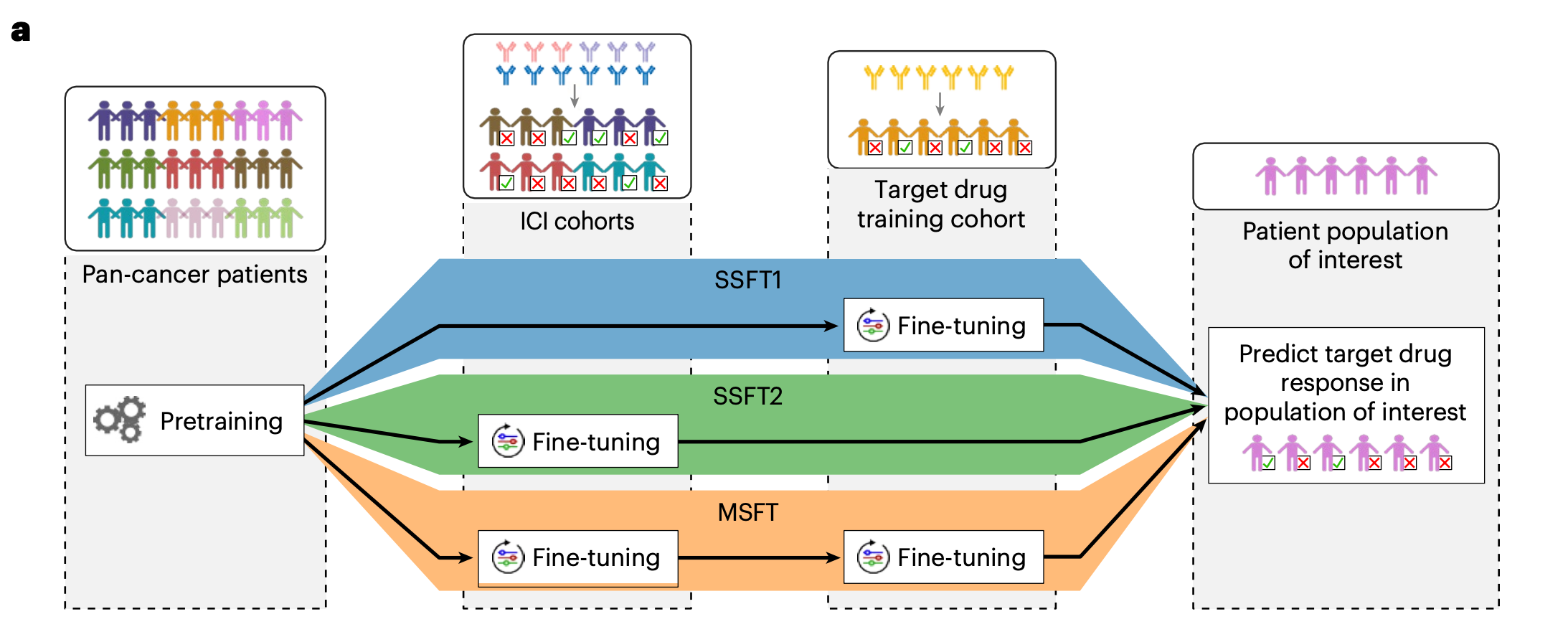
Multi-Stage Fine-Tuning for New Drugs and New Cancer Types
In drug development, early clinical trials often contain only a small number of patients for a target drug. This makes indication selection and patient enrichment difficult. COMPASS addresses this with multi-stage fine-tuning (MSFT), a domain-adaptation strategy that progressively transfers knowledge from pan-cancer pretraining to heterogeneous ICI cohorts and then to a target drug or combination regimen.
The study compared single-stage and multi-stage strategies. SSFT1 uses only the drug-specific cohort, SSFT2 uses broad ICI cohorts, and MSFT first adapts to pan-ICI data before fine-tuning to the drug-specific setting. MSFT consistently outperformed single-stage strategies, especially in small-sample settings where direct fine-tuning is vulnerable to overfitting.
Zero-Shot Prediction with COMPASS-NFT
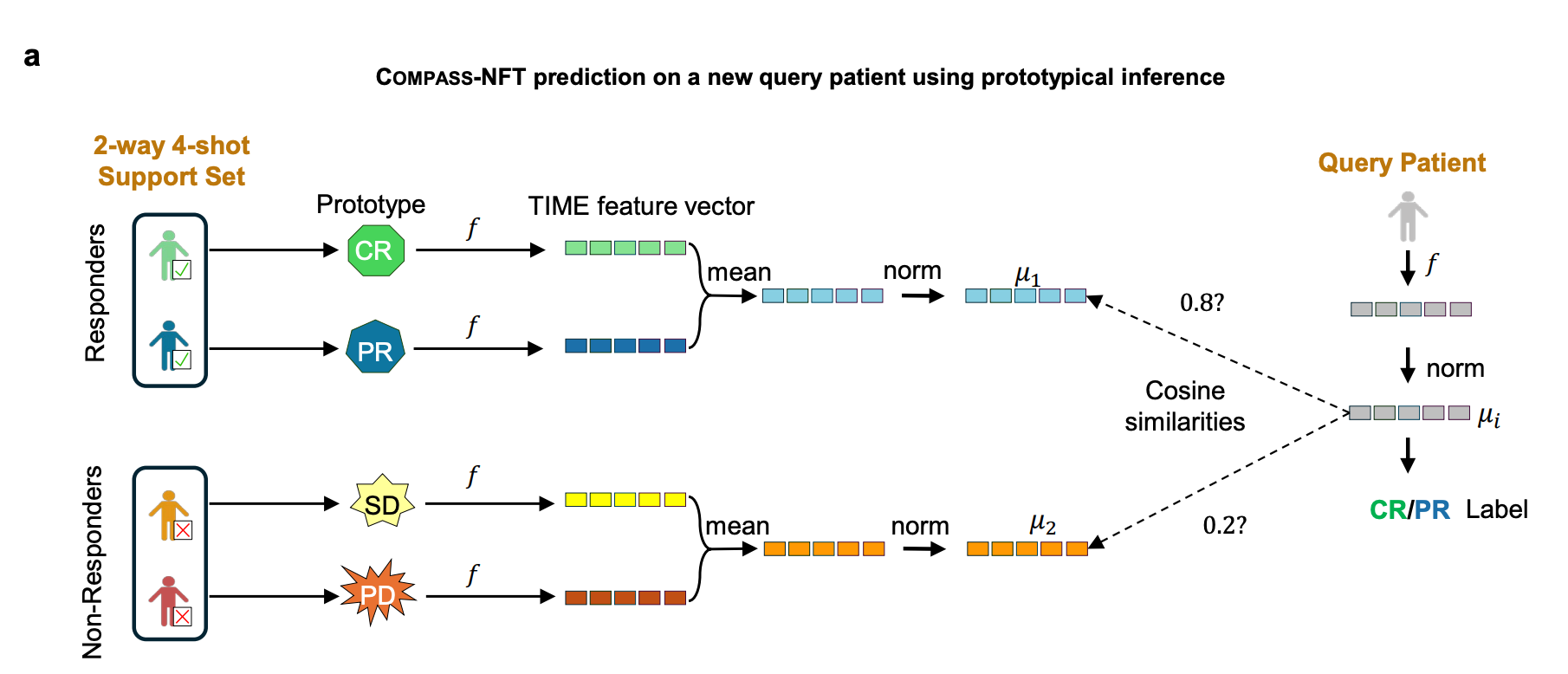
When the target cohort is extremely small or response labels are unavailable, even lightweight fine-tuning may overfit. COMPASS therefore includes a no fine-tuning mode, COMPASS-NFT, which freezes all pretrained weights and performs prototypical inference directly in the 44-dimensional concept space.
In this setting, a small labeled support set defines responder and non-responder prototypes. A new query patient is embedded into the same TIME concept space, and its label is assigned by cosine similarity to the class prototypes. This gives COMPASS a full spectrum of adaptation strategies, from zero-shot inference to full fine-tuning, depending on cohort size and label availability.
From Prediction to Survival and Resistance Mechanisms
Prediction is only part of the story. For clinical and translational use, we also need to understand why a model makes a prediction and what biology may drive response or resistance.
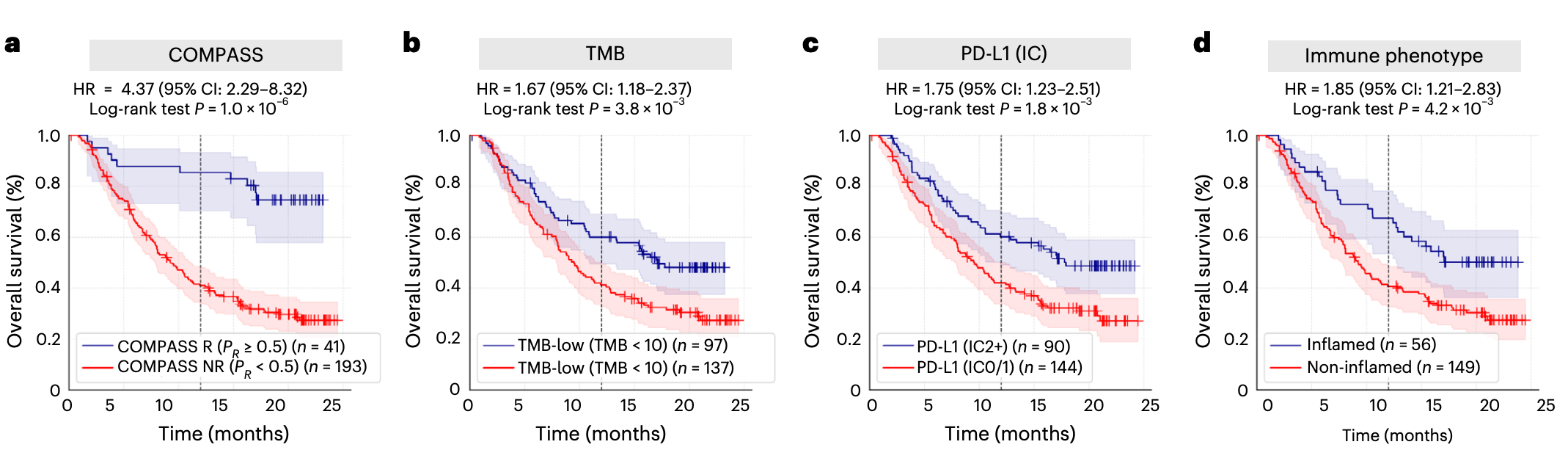
In the IMvigor210 metastatic urothelial cancer cohort treated with atezolizumab, patients predicted by COMPASS as responders had substantially longer overall survival. COMPASS also outperformed traditional indicators such as TMB, PD-L1 IHC, and immune phenotype in stratifying survival.
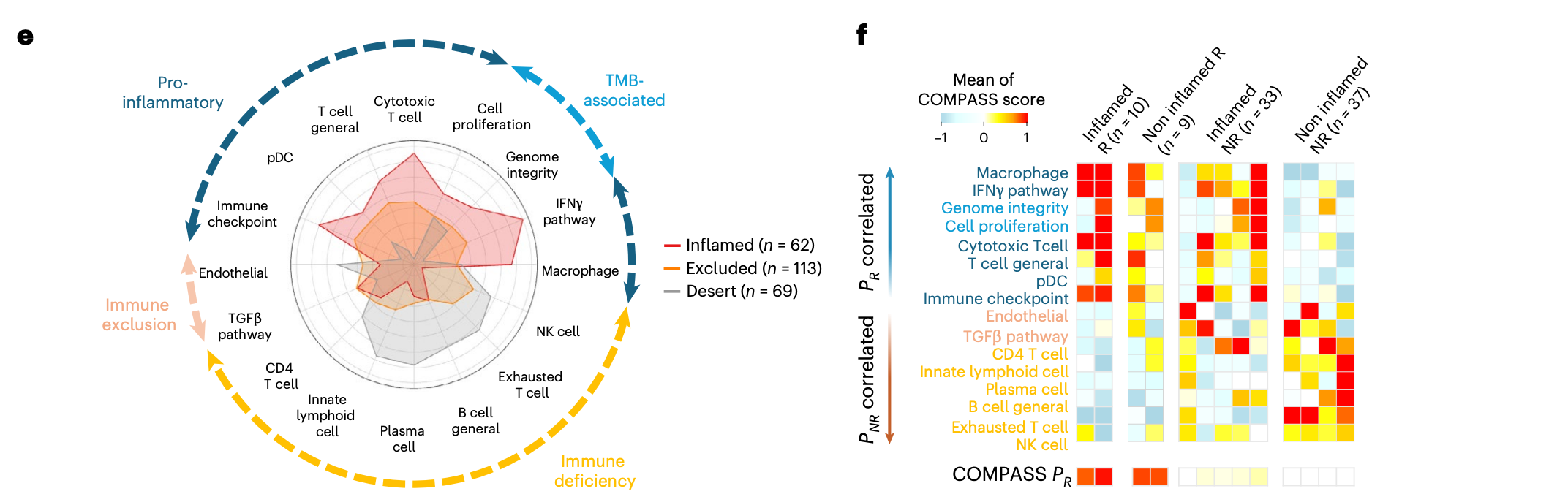
The interpretable immune concepts further reveal mechanisms that are difficult to capture with broad immune phenotypes alone. Some immune-inflamed tumors contain T cell infiltration but still fail to respond; COMPASS suggests that these cases may involve TGFβ signaling, endothelial exclusion, CD4+ T cell dysfunction, or B cell deficiency. Other immune-desert non-responders are dominated by immune-deficient programs.
Personalized Response Maps
One of the most distinctive features of COMPASS is its ability to generate a personalized response map for each patient. The map decomposes prediction across five levels: gene expression, encoder representation, granular immune concepts, high-level TIME concepts, and final response probability. Attention weights highlight which connections matter most.
These maps turn a black-box score into a traceable hypothesis. For an immune-inflamed responder, the prediction may be driven by broad IFNγ and cytotoxic activity with little immunosuppressive signal. For an immune-inflamed non-responder, the map may reveal TGFβ signaling and B cell deficiency. For an immune-desert non-responder, immune-deficiency features may dominate.
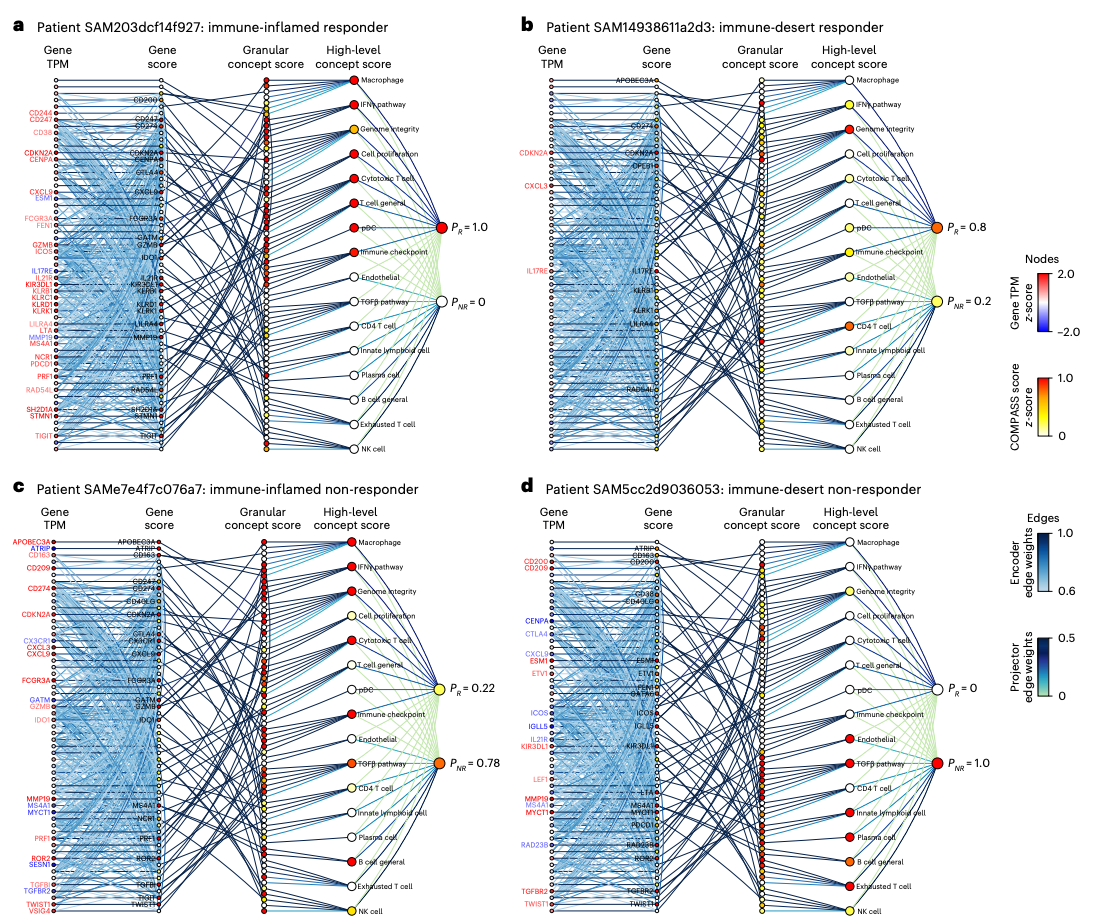
Concepts as a Modular Foundation for Downstream Clinical Models
COMPASS concepts are useful beyond the response model itself. They can serve as modular representations for downstream clinical predictors. The paper tested this by integrating COMPASS with Clinical Transformer, a survival model that applies self-attention across concept or feature dimensions.
Compared with ssGSEA-based inputs, COMPASS learned concepts provided a stronger representation. Adding Clinical Transformer attention on top of COMPASS concepts further improved survival prediction, supporting a modular strategy: use an interpretable transcriptomic concept encoder as a reusable foundation for downstream clinical AI models.
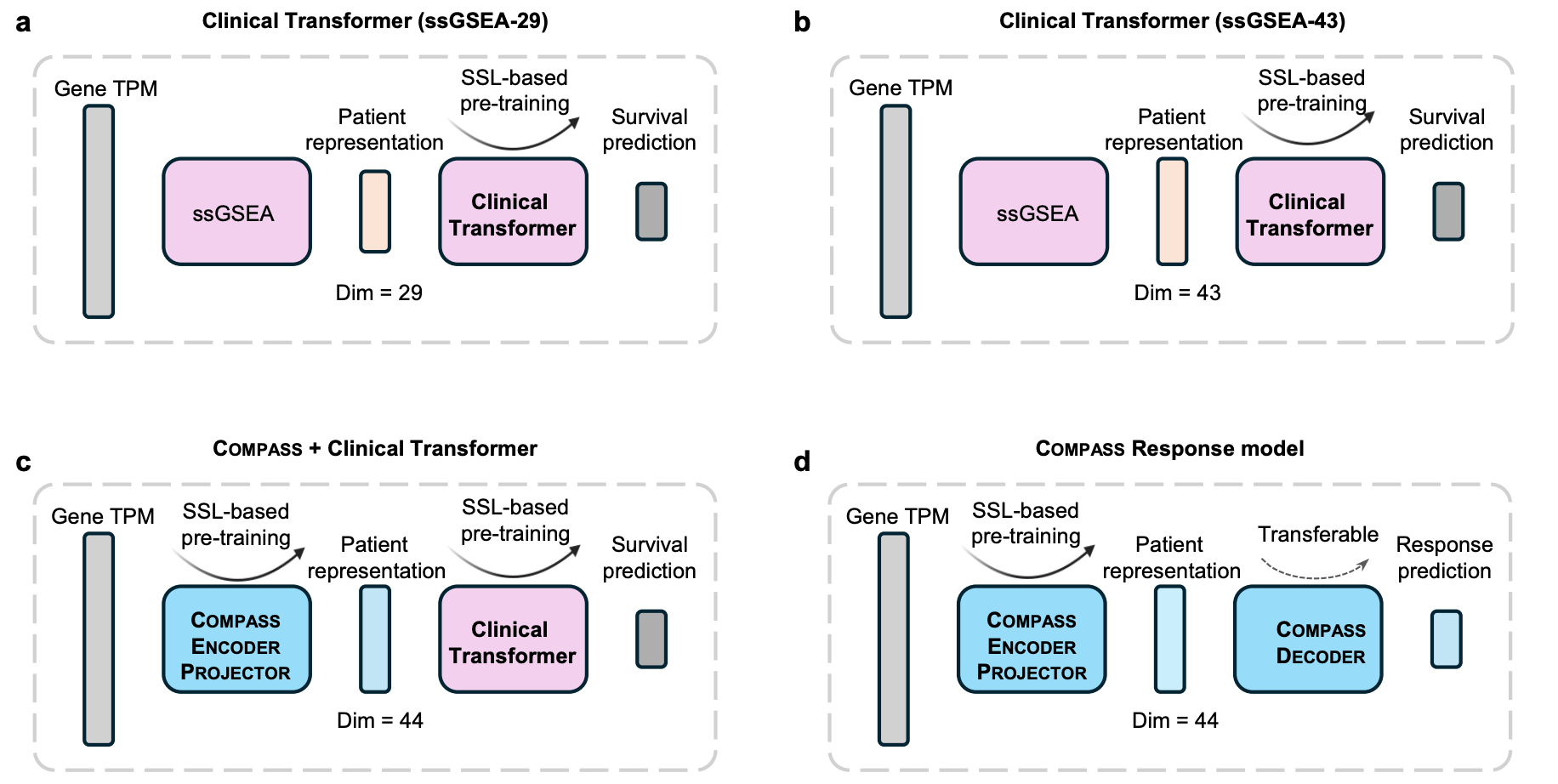
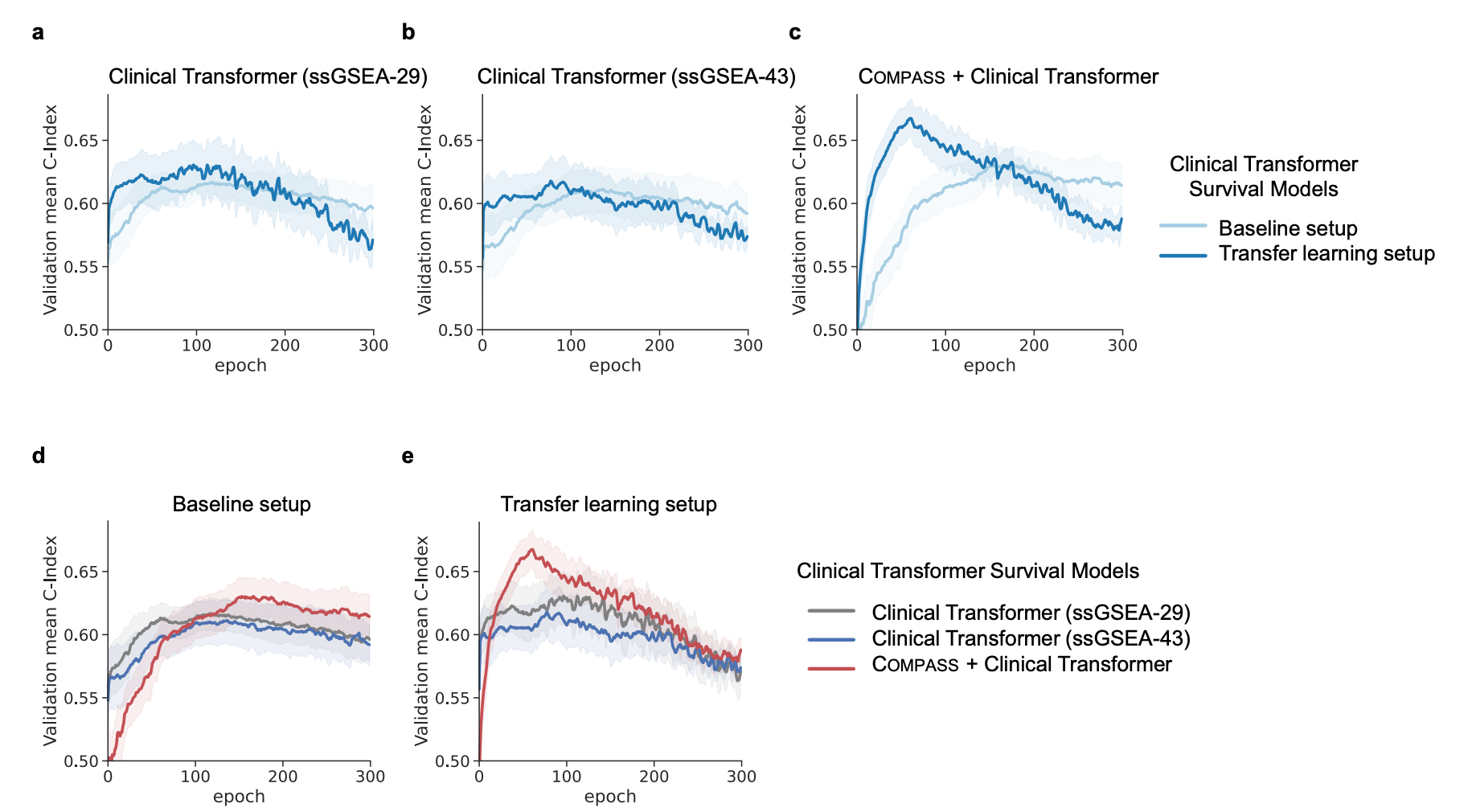
What This Means for Precision Immunotherapy
COMPASS points toward a new paradigm for AI-guided immunotherapy: models that combine broad pretraining, small-data adaptation, and interpretable biological concepts. The goal is not to replace clinical judgment, but to provide a robust computational layer that helps researchers and clinicians reason about patient heterogeneity, therapy selection, and mechanisms of resistance.
For drug development and clinical translation, COMPASS may support three directions:
- patient stratification for immunotherapy and more efficient clinical trial enrollment;
- indication selection by estimating whether a treatment strategy may transfer to new cancer types;
- hypothesis generation for resistance mechanisms and rational combination therapy targets through personalized immune concept maps.
At the same time, COMPASS remains an exploratory research tool. It should not be used as a standalone basis for clinical decision-making or to deny patients immunotherapy. Prospective clinical validation, assay standardization, and multi-center testing are essential next steps.
For AIDDPM Lab, this work also opens several directions we are actively pursuing, including lower-cost Nanostring-style clinical panels, new cancer-specific validation studies, response-map-based target discovery, and AI-guided patient stratification for precision immunotherapy trials.
Resources
- Nature Medicine paper →
- COMPASS project website →
- Online COMPASS predictor →
- Feature extraction tool →
- Code on GitHub →
- Harvard Medical School news story →
Paper Information
Shen W., Moon I., Nguyen T.H., Li M.M., Huang Y., Nair N., Marbach D. & Zitnik M. Generalizable AI predicts immunotherapy outcomes across cancers and treatments. Nature Medicine, 2026. DOI: 10.1038/s41591-026-04502-7.
Acknowledgments
Many thanks to all mentors and collaborators who made this project possible, especially Daniel Marbach and Marinka Zitnik for their guidance, support, and inspiration throughout this work. We also thank Intae Moon, Thinh H. Nguyen, Michelle M. Li, Yepeng Huang, Nitya Nair, and all collaborators for their important contributions.